In this post, we take a look at this paper, which introduces a simple, yet interesting approach to solving a multi-vehicle path planning problem.
My implementation of the algorithm that was used to evaluate its performance and generate all the results in this post can be found here
Problem
The paper tries to tackle the issue of finding fuel optimal paths for multiple vehicles, given vehicle-obstacle and vehicle-vehicle collision constraints. The paper being more than two decades old, makes this a rather interesting read because it comes from a time well before the advent of sophisticated trajectory optimization methods we see today.
The fuel optimal cost function is formulated as a linear program, with the collision constraints being represented as linear constraints using binary integer variables. The entire problem is thus cast as a Mixed Integer Program (MIP), and taking into account that it accounts for multiple vehicles, the rest of the post shall refer to the algorithm as MVMIP.
Formulation
Preliminaries
The planning problem under consideration is usually cast as an optimization problem with a quadratic cost.
Where represents the robot state and represents the control input that need to be executed at each time step. and are the cost matrices for the quadratic cost.
Due to the fact that we want to cast this as an MIP, this cost will be cast as a linear cost that looks like:
Here and are cost vectors that form the linear equivalent of the quadratic cost. is a vector denoting the absolute values of the vector being operated on.
Objective
As is common in these scenarios, to make the problem tractable, it is discretized into time steps. Separate costs vectors are also introduced for the final state . This is a familiar trope in planning and allows for greater flexibility in generating the results we need, which we will see later.
and are the variables of the optimization and represent the robot’s trajectory and control inputs required to generate the state trajectory. Solving for these for each robot will essentially solve the MVMIP problem. is the initial state of the robot and is not a variable. denotes the expected or required final state of the robot. is the control input at the first time step and is a variable, but is not as we don’t expect to apply any control on the last step where the robot is expected to have reached .
As mentioned, applies to each state vector through , with having a corresponding cost term of
The objective as we see now tries to minimize the cost on the state and control. The minimum value for this objective is when both states and control inputs are zero but this is not what we desire. Driving the control inputs to zero is fine as we’re looking for fuel optimal paths, but driving the state also to zero is not the behavior we want as we’re not constructing a regulator.
Ideally we would want the state of the vehicle/robot to reach the final state . So instead of driving the state to zero, we would like the problem to drive it to the required final state. This can easily be done by replacing with which makes it so that instead of driving , we are driving which means driving .
And finally, we get to the multiple vehicle part of this whole thing, where we have states and control inputs for each required vehicle. The state and control of the vehicle will be represented as and the control input as . The objective function for the vehicle is now (Note that some of the constant terms like can be ignored):
The question now is how does one frame this objective that has terms as a linear function with linear constraints? To answer this, we take a quick detour to go over a known result in linear programming.
Consider the following optimization problem:
Where . This can be written as:
Where here is just the absolute value of the element of .
We can now introduce slack variables for each such that and frame the objective as a linear function in . The objective will now be a minimization over and the constraint makes it so that minimizing will minimize each
This is nice because it lets us keep a linear objective and represent the absolute inequality as two linear inequalities:
With this knowledge, we can now introduce slack variables and for and respectively. Representing the objective as an LP in these slack terms, along with taking the sum for every vehicle (assuming vehicles), we have the final objective function:
Note that we have the slack constraints for each element of the state and control vectors.
Vehicle-Obstacle Collision Constraints
Before we get to this, let’s take another detour to look at a concept that is something of a pre-requisite.
Let’s say we have an optimization problem of the form
Solving this would mean solving for the fact that ALL of the constraints need to be satisfied.
AND AND , etc.
But what if we want don’t want each constraint to be satisfied? What if the our requirement is that at least one of them be active?
OR OR , etc.
In this case, we can use a variant of the big-M method to help reframe the constraints. First we introduce binary integer variables for each constraint. We also introduce a constant that is an extremely large number relative to the range of the functions. The constraints can then be written as:
Let’s dissect what’s happening here. Each can be either 0 or 1.
if a particular (for the constraint), we have:
And given that , this constraint will always be satisfied, irrespective of the value of . if a particular , we have:
Which is just the original constraint.
So if , then this means that each constraint would trivially be satisfied, so this would be equivalent to not having any constraints at all.
On the other hand if , then then problem will be treated as an optimization problem where each of the original constraints need to be satisfied.
What happens if at least one of the values are restricted to be ? This would mean that at least one of the constraints (the ones where ) will need to be satisfied (active), but the rest wouldn’t need to be active as they would be trivially satisfied due to .
Hence by having an additional constraint on the sum of values, restricting them to a maximum value of , we can guarantee that at least one . This then translates to our desired property of the optimization problem requiring only one of the constraints to be satisfied!
Equipped with this, we can now look at how the paper frames collision avoidance constraints. It is assumed that each obstacle is rectangular and the vehicle moves in a two dimensional space (It can easily be extended to 3D). Each vehicle/robot is also assumed to be a point.
If is the current state of the vehicle, we assume that the state contains some and , which correspond to the and coordinates of the vehicle in 2D space. If the mid point of the obstacle is and its size is , we can compute the bottom left and top right points as:
The vehicle at will avoid the obstacle (not be in collision) iff:
We require at least one of these constraints to be true. So we can use the big-M method to reframe these constraints!
These constraints ensure that the vehicle avoids the obstacle, but offers no additional clearance from it. It also does not account for the vehicle itself having volume. In order to account for these, we can add additional clearance terms and that encapsulate the size of the vehicle and any additional clearance to obstacles. Additionally we also express the constraints for the vehicle and the obstacle.
Moving Obstacles
This framework easily extends to representing moving obstacles as well. Instead of having the min and max coordinates of the obstacle fixed at and , we can have its coordinates be different at each time step . Given the velocity of the object at each time step, we can estimate its coordinates and use them in the constraints as shown:
Vehicle-Vehicle Collision Constraints
Vehicle-vehicle collision constraints can be represented the same way as vehicle-obstacle constraints. The only difference being that the constraint is between the coordinates of the and vehicles at the time step for every pair of vehicles. Instead of using the minimum and maximum coordinates of the rectangular obstacles, we represent the volumes of the vehicles and any additional clearances through distances for each pair of vehicles.
Note that we have a different set of binary variables here.
Extensions
The entire problem has now reduced to a mixed integer linear program. The objective is a linear function and the constraints are linear in the state, control and binary variables for collision. Additionally, we can also enforce state and control limits for each vehicle as upper and lower bounds for each of these variables.
Please refer to the paper 1, to see the entire LP written out in all its glory. The state and control constraints can also be formulated as approximate second order ball constraints using a collection of linear constraints (instead of box constraints) as seen in 2.
The papers model the obstacles as being rectangular, but we can always extend it to being general convex polygons. In this case, we would want the vehicle to lie outside the intersection of the half-spaces formed by the edges of the polygon.
Where represents the space inside the convex sided polygon.
Implementation
The MVMIP can be solved by setting up the objective and constraints and passing it to a linear solver that supports mixed integer programming. My implementation uses Google’s OR-Tools
The problem can be treated as a one-shot fixed arrival time problem where we set a large time step () and solve for each vehicle trajectory. This method ensures that there is only a fixed initial cost to run the algorithm and we don’t make any adjustments later. The advantage of this method being that we are guaranteed to find the optimal solution to the initial problem setup.
The fixed long horizon method would not run well on a real system running in a dynamic environment. For such systems, we can cast it as a shorter receding horizon problem and execute the first few commands of the solution MPC style. This will make the MVMIP responsive to dynamic changes to the environment, but also comes at a cost for executing the algorithm at every timestep and will lead to a solution that will theoretically not be optimal (But is about the best it can do given that the environment is only going to be partially observable).
The biggest pain point of the algorithm is how the number of variables and constraints scale with , and . As we’ll see the time take to solve the MVMIP will explode as we deal with multiple vehicles and obstacles in a long horizon setup.
Results
Visual Solutions
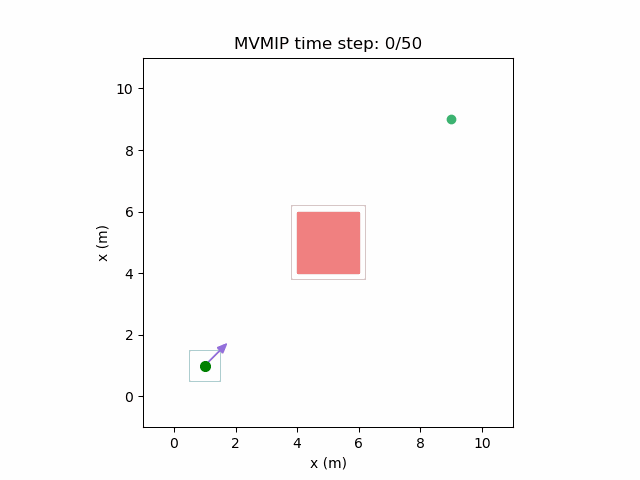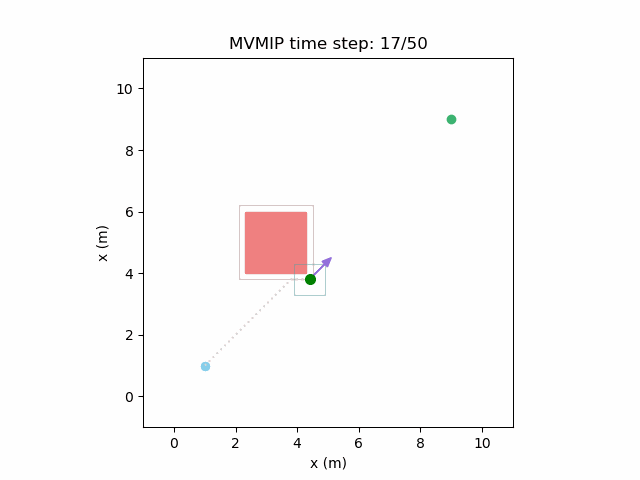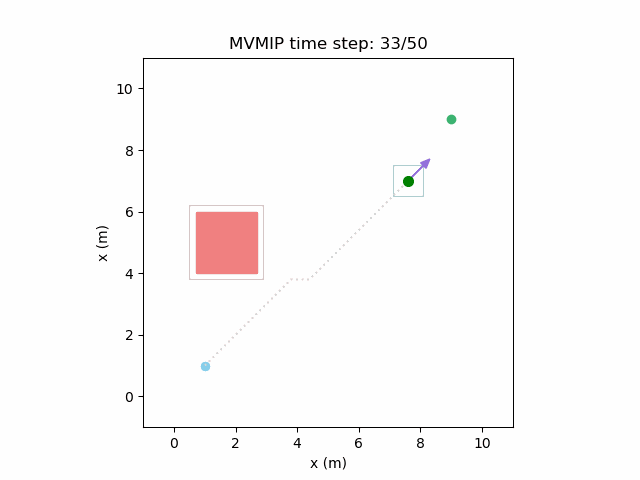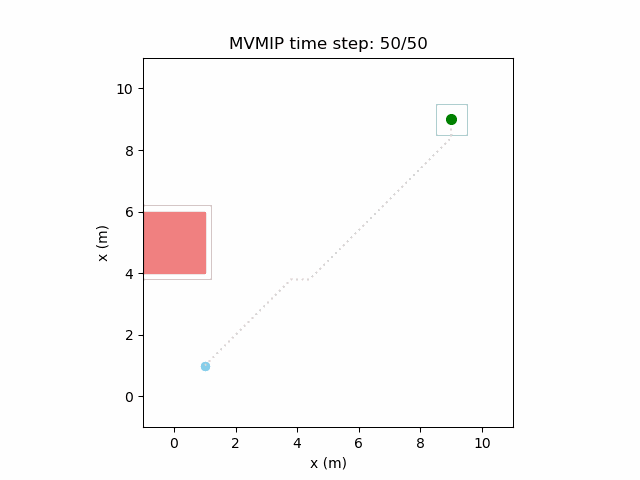
Running the MVMIP for a single vehicle and obstacle results in this:
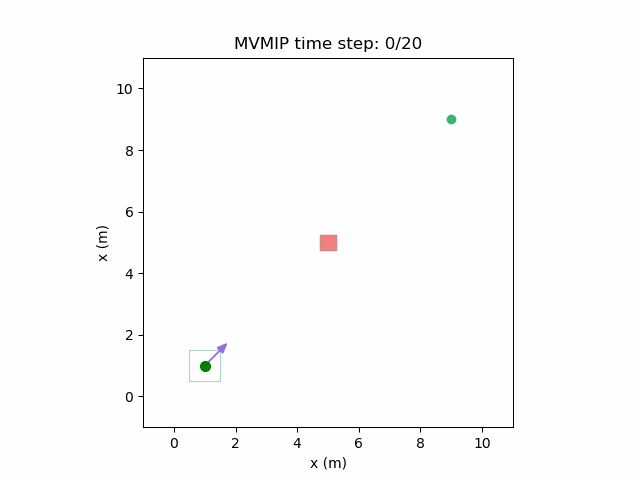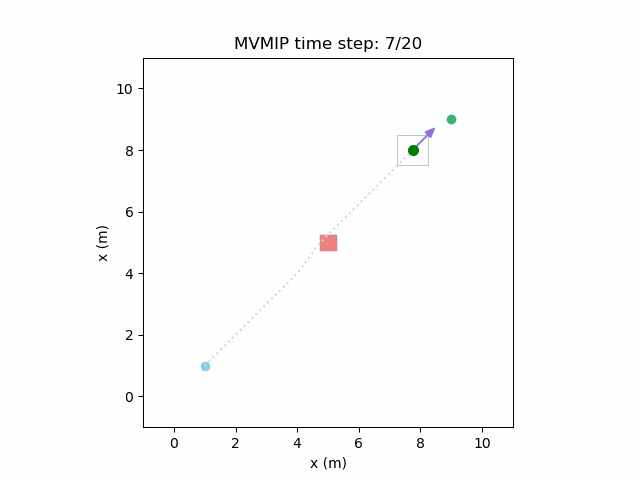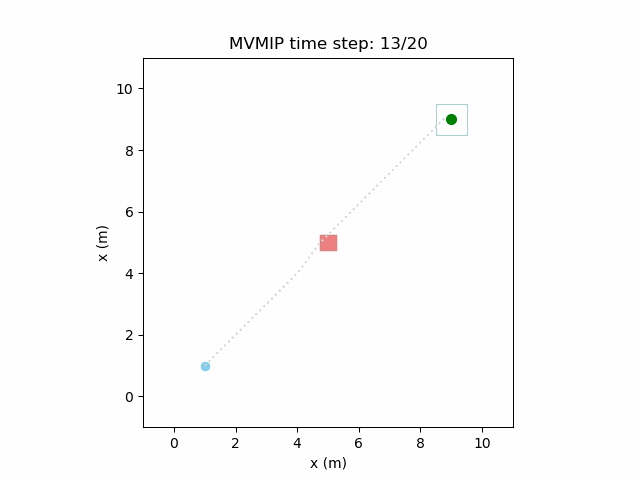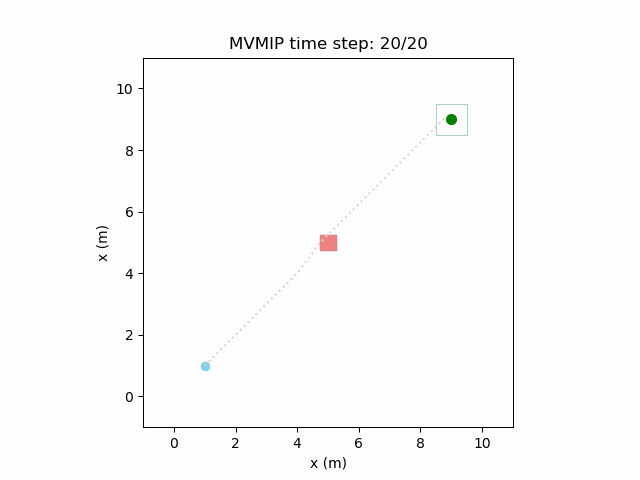
Turns out that we’ve run into a classic problem in planning caused due to discretizing the problem. Because we only have collision constraints at each state and not in between successive states, if our control inputs have large limits, the MVMIP can find a solution that jumps through obstacles. It thinks that the trajectory is feasible because each state alone is collision free, but the reality is that the robot can pass through obstacles between discrete states.
How do we solve this? The simple LP formulation of the MVMIP makes it rather difficult to express anything too complex. We could model the space between successive states as another convex polygon and set up approximate constraints. An easier and less expensive way would be to just reduce the bounds of the control inputs such that each control step is guaranteed to move the robot by a maximum distance that is less than the size of the smallest obstacle.
This obvious has its own downsides of limiting the max control input that can be applied, among others limitations, but keeps it simple in the spirit of the algorithm.
Fixing the control limits now gives us the solution that we need:
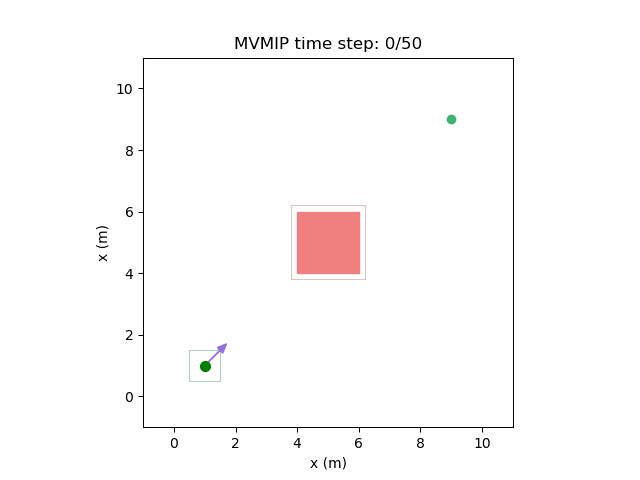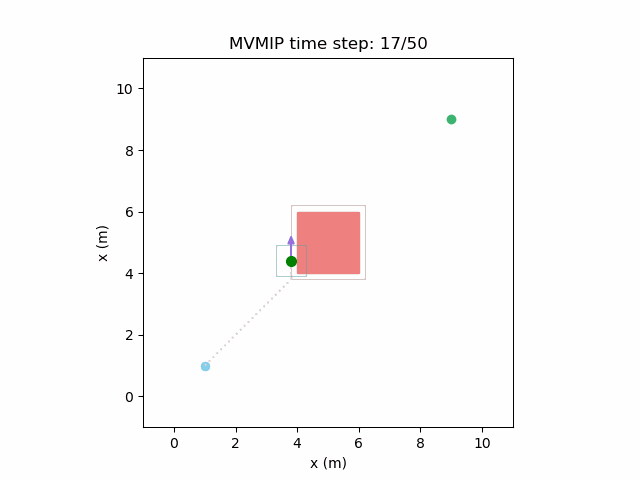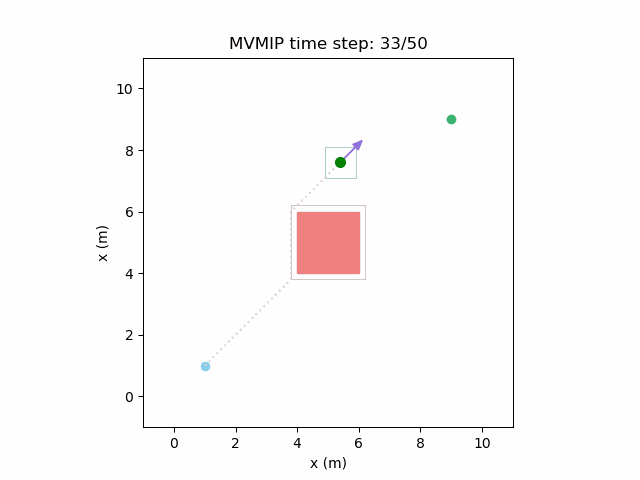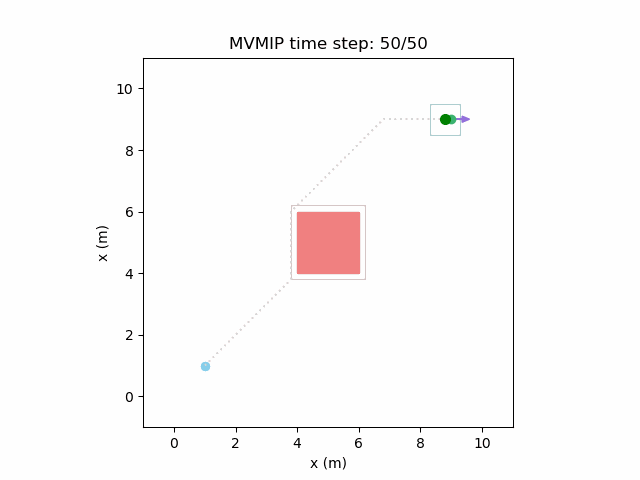
We can see that the vehicle maintains clearances to the obstacle as required, as is visually seen in the drawn boundary around the obstacle. The boundary around the vehicle itself is for vehicle-vehicle clearance.
We can verify that it works as expected even with moving obstacles:
Now we can start messing around with some of the costs. To break it down, we have the vector costs on the state, vector costs on the control and vector costs on the final state. The costs encourage the robot to make progress towards the final state . The costs encourage the robot to minimize the total control effort exerted and the costs encourage the robot to reach the goal by any means necessary.
By changing their relative magnitudes, we can achieve a range of behavior and decision making. If and are kept low and is high, the robot has no real incentive to move at all as it can minimize its total cost by staying in place. Any movement would accrue a large cost due to the high term which would overpower any reduction in or costs due to moving closer to the final state.
Making and moderately high while keeping a high value of can make the robot make progress towards the final state but stop when it has to make too much of a detour as that gets translated to applying higher control effort on average due to the longer path it will need to take. This can be seen here:
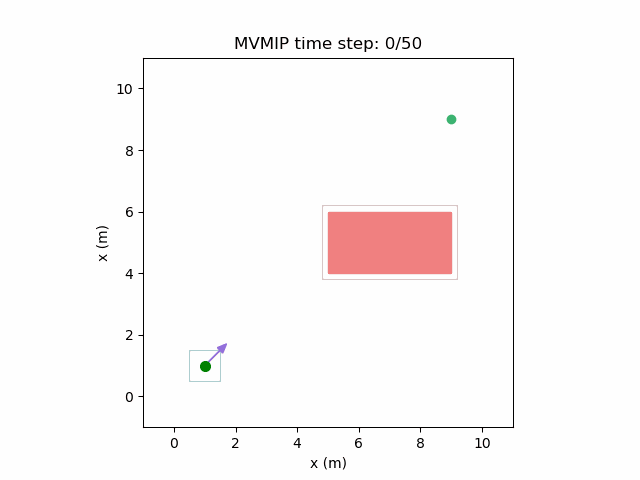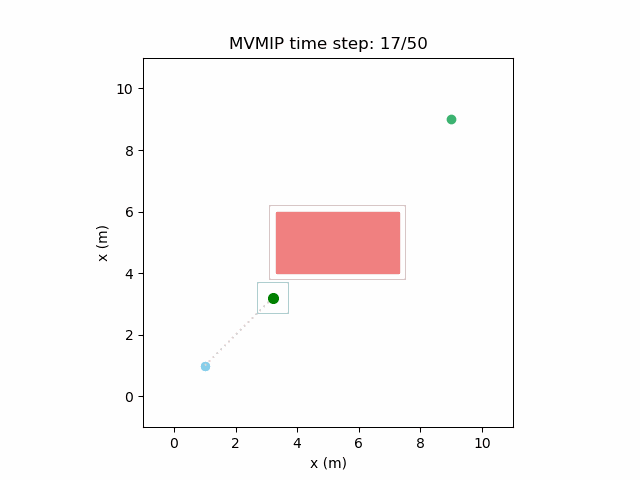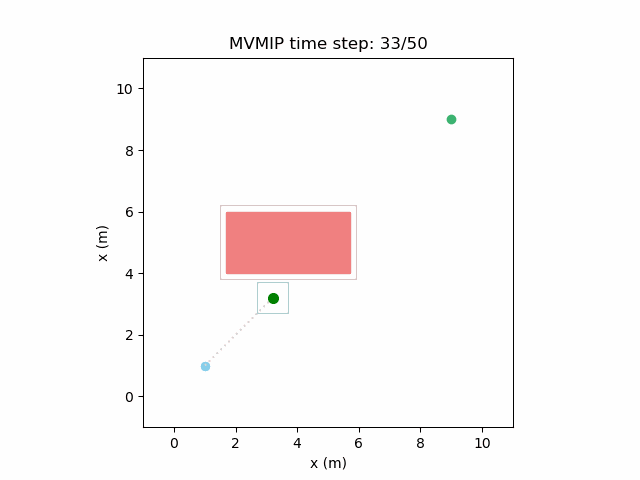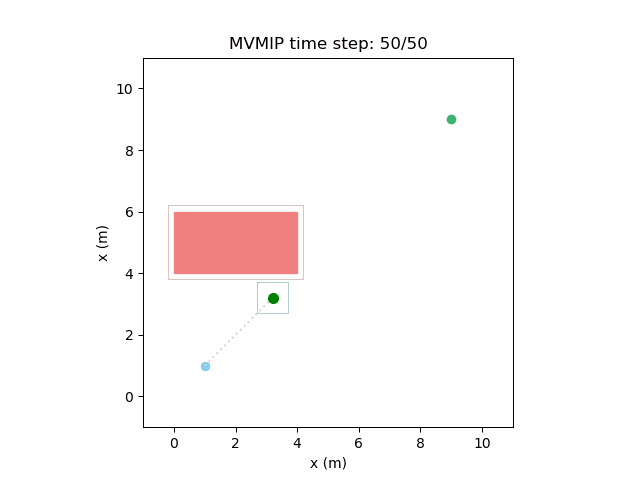
We can further see the effects of different costs on this environment with multiple moving obstacles. High and , along with low will manifest in the form of aggressive decision making as expected.
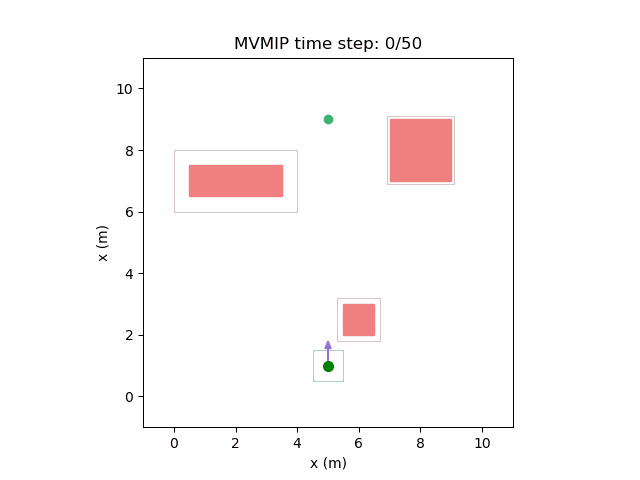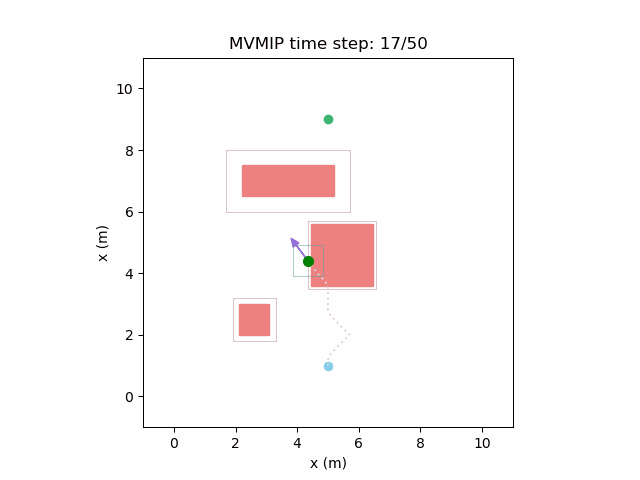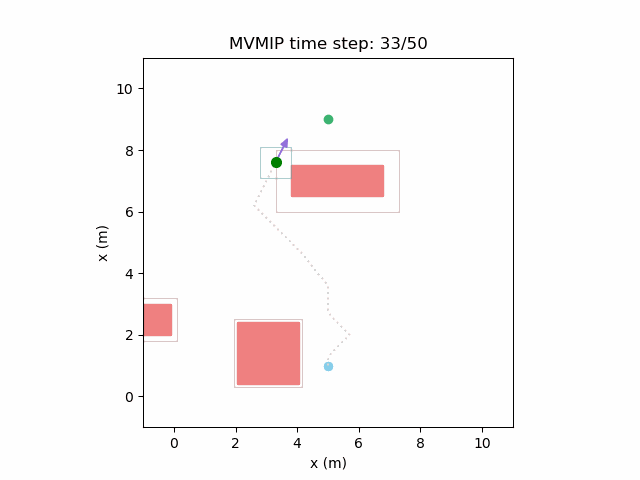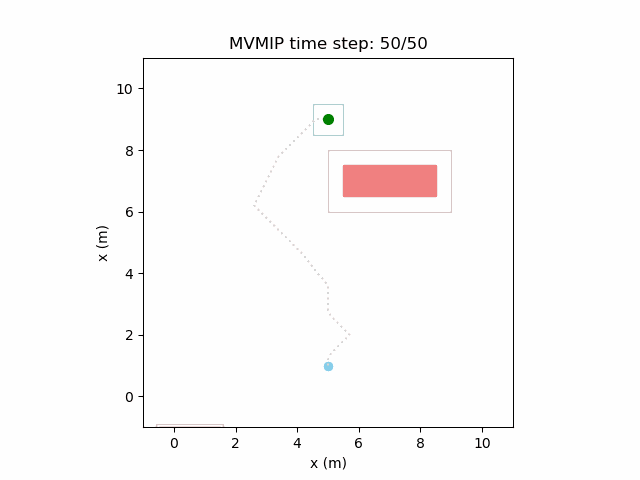
Reducing and increasing can make it act more conservatively.
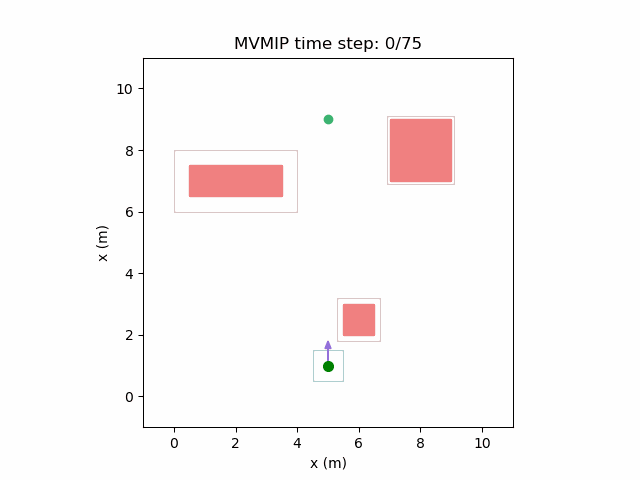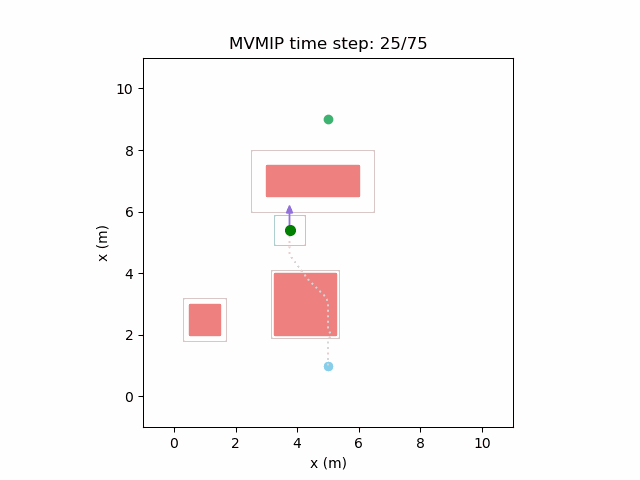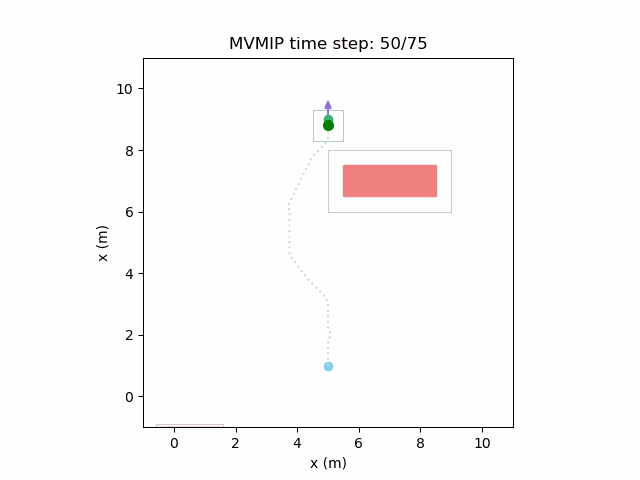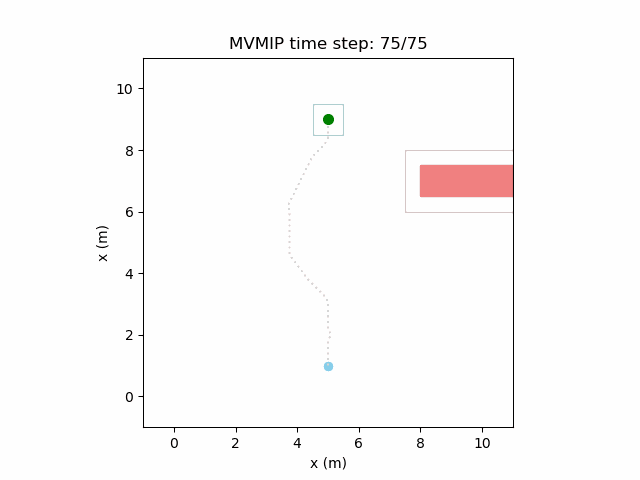
And finally reducing and increasing further can make it extremely passive. In this case it patiently waits for each obstacle before making its way forward. Note that needs to be very high in this case to reward it for making it to the final state. Otherwise, it will refuse to move at all.
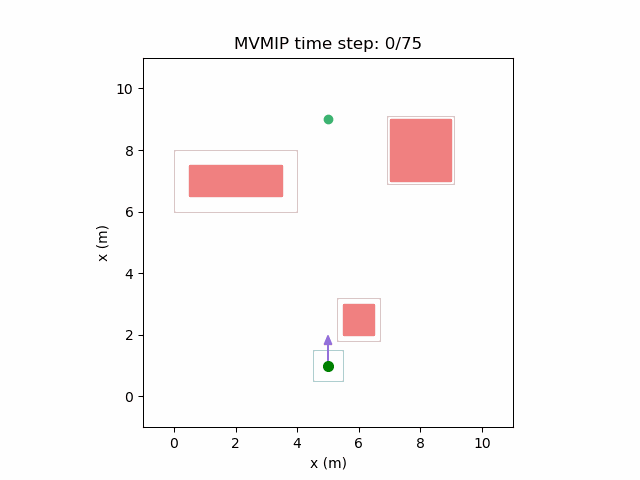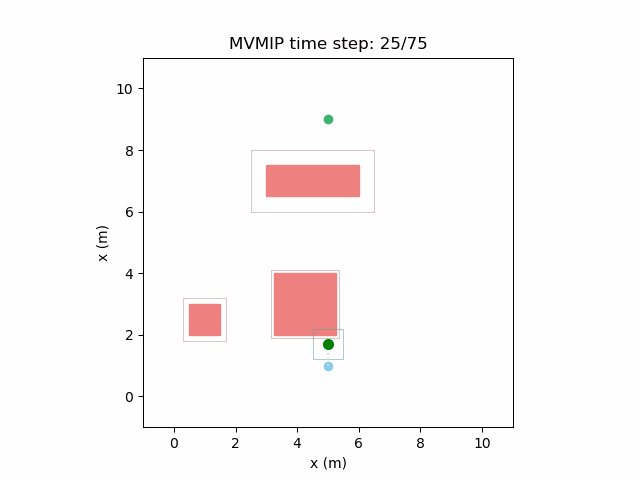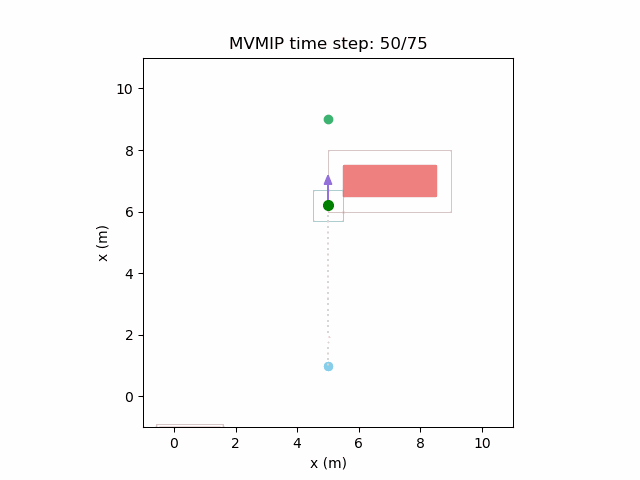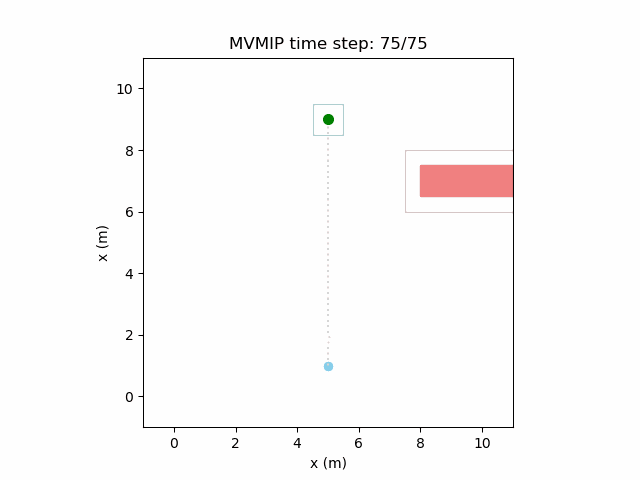
And finally, we have an example of the MVMIP in all of its glory — multiple vehicles along with multiple obstacles.
Each of the vehicles here have different costs and we can clearly see that they each have a different level of aggressiveness in their decision making.
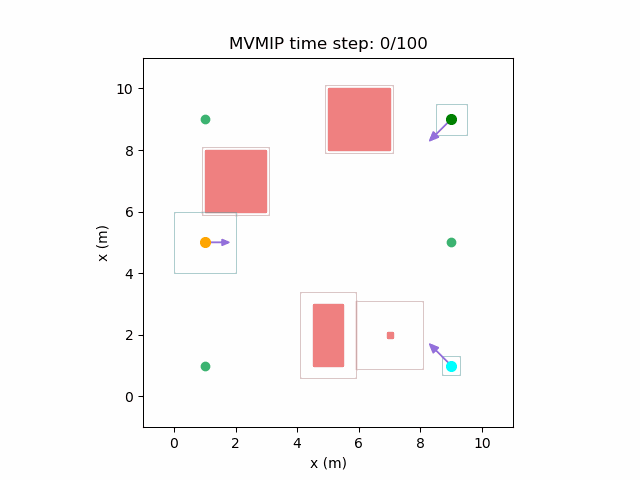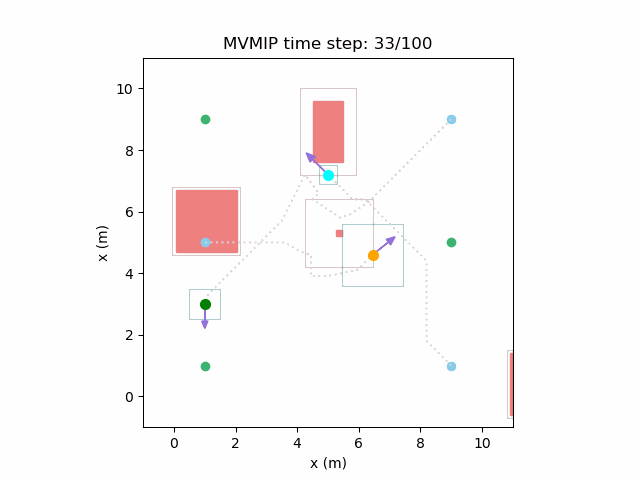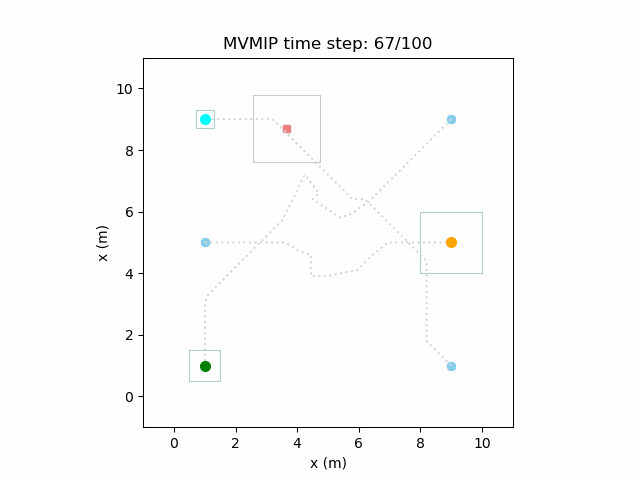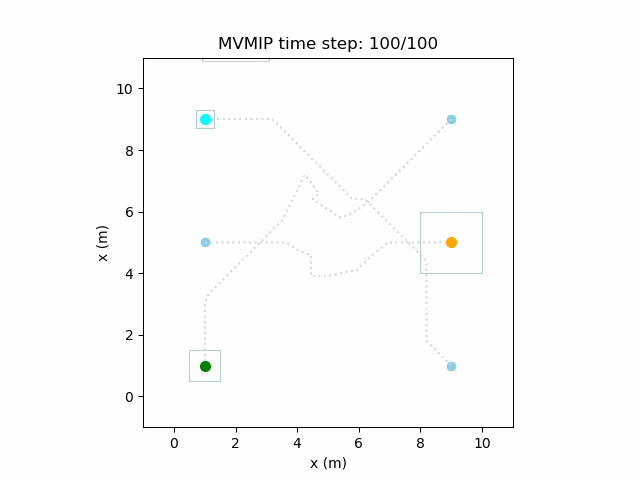
Computational Cost
How expensive is it to solve the MVMIP?
For small problems (Like the first one shown here), it can be pretty quick.
The single vehicle, single static obstacle case had 240 variables and 300 constraints and was able to be solved in around 10 ms.
The last one — multi vehicle, multi dynamic obstacle case had 8400 variables and 10500 constraints and took upwards of 30 min to solve. Obviously there are other factors such as how easy it is to actually find a solution given the constraints and so on, but in general the solve times explode as we have more vehicles and obstacles.
Some of this can be mitigated by using the receding horizon approach.
References
-
Schouwenaars, T., De Moor, B., Feron, E., & How, J. (2001, September). Mixed integer programming for multi-vehicle path planning. In 2001 European control conference (ECC) (pp. 2603-2608). IEEE. [Link] ↩
-
Richards, A., & How, J. P. (2002, May). Aircraft trajectory planning with collision avoidance using mixed integer linear programming. In Proceedings of the 2002 American Control Conference (IEEE Cat. No. CH37301) (Vol. 3, pp. 1936-1941). IEEE. [Link] ↩
See Also
- Implicit Euler integration using Newton-Raphson
- Understanding TrajOpt
- Setting Up a Robotic Manipulator
- ZMP: Generating Bipedal Walking Trajectories
- Reference: Behavior Cloning for Manipulation
Comments